FreeMask: Rethinking the Importance of Attention Masks for Zero-Shot Video Editing
Authors:
原文链接
Introduction
视频编辑的方法可以分为两类:一类是依赖于外部控制,另一类是依赖于内部控制。
与时间无关的 mask 可能不适合所有的编辑任务,比如形状编辑。
这些方法需要一些其他预训练模型,比如深度估计模型等,从而引入了额外的推理计算开销
直接将专用于图像的模型用于视频处理会出现一些伪影现象
为了解决这个问题,本文提出了 FreeMask ,这主要基于两个观察:
随着去噪的进展,交叉注意力图变得更加清晰
交叉注意力图在中间层表现出最精确,外层噪声太大,而内层由于分辨率低而太不精确
此外,大多数 zero-shot视频编辑严重依赖于源视频和编辑内容的注意力特征的混合,然而,确定最佳混合比例具有挑战性。混合不足可能会导致结构扭曲,而过度混合会产生与原始视频完全相同的视频,这是导致 prompt错位的常见问题。
Method
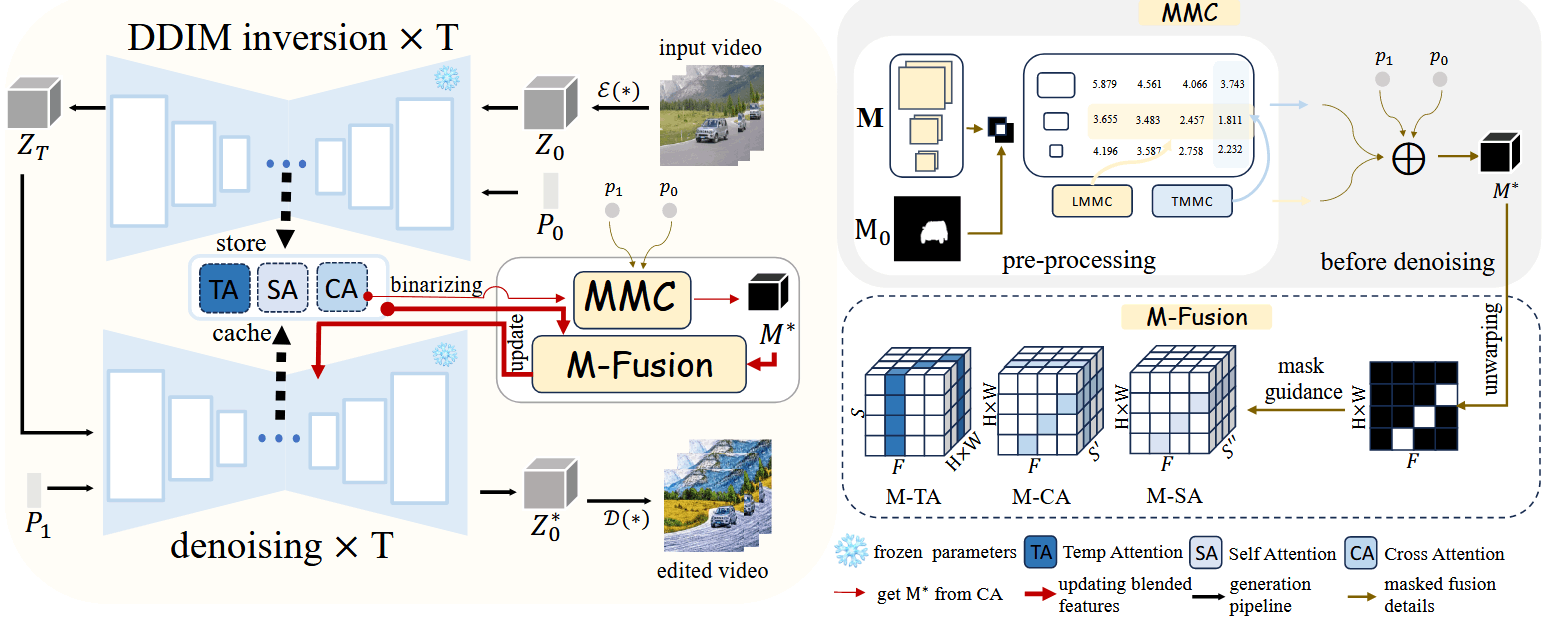
整体流程:
首先生成候选的 mask,计算模型相关的 LMMC 和 TMMC 指标
在执行 DDIM 反演之后和去噪之前,我们计算语义自适应 MMC 指标来选择注意力掩模
在去噪过程中,我们应用掩模来指导不同类型注意特征的融合
Mask Matching Cost (MMC)
在计算 MMC 之前,首先生成候选的 mask,包括所有的 cross-attention layer,这些候选 mask 在 DDIM inversion 阶段来获得。具体来说,对于每个 cross-attention,只选择有物体的单词,并且使用一个阈值得到二值化的 mask
LMMC 和 TMMC 的计算方法:使用视频数据集 DAVIS 中真实的 segmentation 和候选 mask 做一个 MIoU,分别在时间维度和层维度进行平均,得到两个集合分别代表 LMMC 和 TMMC ,其中最佳的时间数和层数分别为 t ∗ l ∗
论文发现交叉注意掩模的清晰度变化在视频扩散模型中很常见,并且在模型级别是系统化的,这意味着变化的规律性与模型架构有关,而不是与输入视频有关。
交叉注意力匹配精度呈现倒 U 型。这种差异源于外层包含低级空间信息,而内层捕获高级空间信息。文本嵌入是高级信息,语义级别的相似性是有效视频文本匹配的先决条件,因为交叉注意力图计算文本嵌入的查询和视频潜在密钥的矩阵乘积。尽管如此,语义匹配精度并不等于掩模匹配精度,因为最内层的分辨率太低,导致 LMMC 更高。
在去噪过程中,时间步是按反向运行的,随着 T 减小到 0。起初,在较高的时间步下,潜在噪声更加显著,这导致低级空间信息的准确性较差,进而影响高级语义匹配的精度。
在得到 LMMC 和 TMMC 后,可以选择出更加合适的 mask,用 M ∗ δ δ
δ = { 1 if p 0 = p 1 0 if p 0 ≠ p 1 M ^ t l = { M t l ∗ , if δ = 0 , M t ∗ l ∗ , if δ = 1. 在做编辑中,首先将其 mask 进行一个转换:
对于风格化这样的任务,主体物体没有发生变化,δ m ∗
对于更换主题物体这样的编辑,δ m ∗
References
正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数... 载入时分秒...
总访问量